
What is overfitting?
In machine learning you’re usually trying to predict outcomes for values that you’ve never seen before based on training data that you have seen and know about.
So overfitting is basically when your model is trained so specific on the training dataset that predictions are bad for data that the model has never seen before.
Generally speaking you could say that your model will start to overfit as soon as the test error starts to increase where the training error is still decreasing.
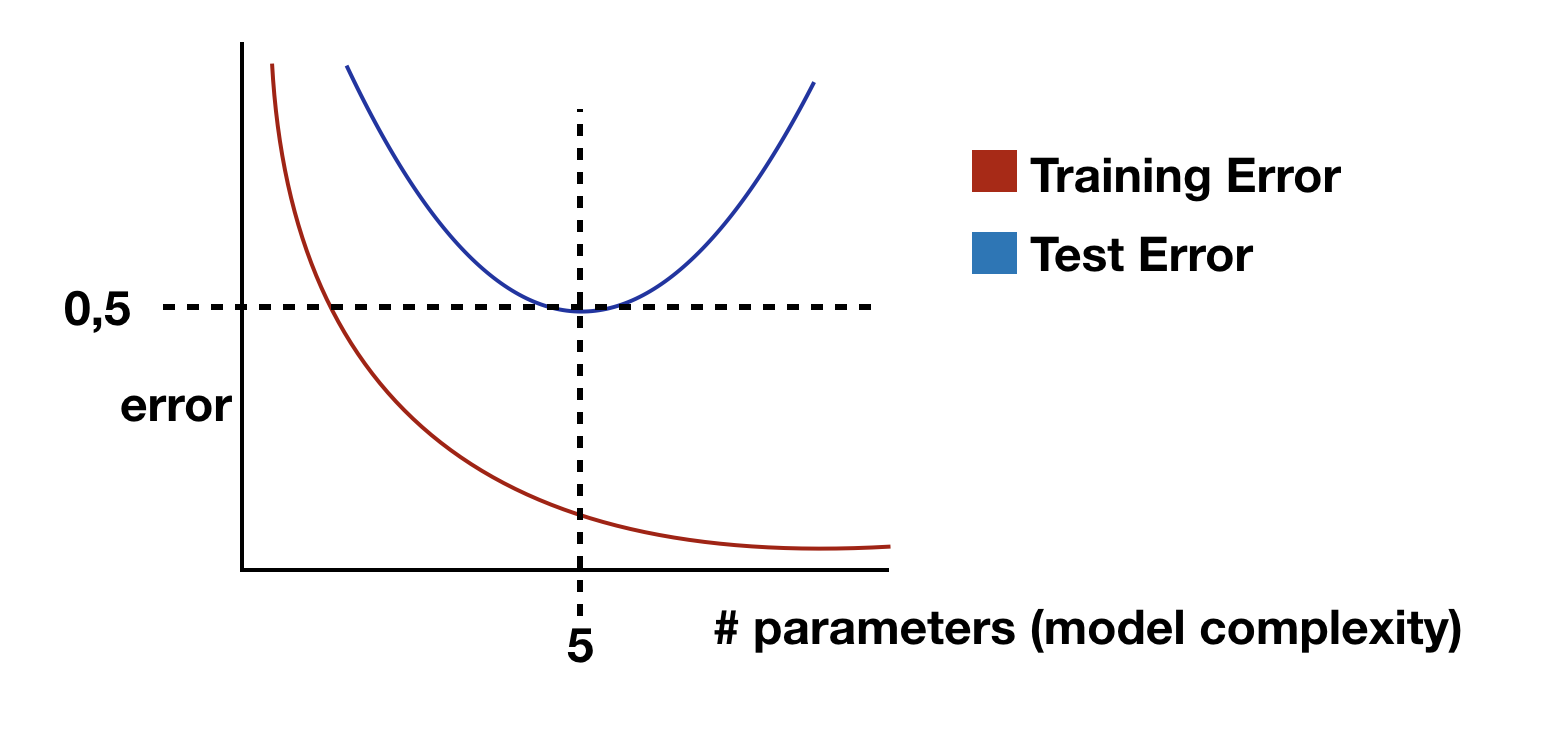
As you can see in this figure this model has a sweet spot at 5 independent parameters and starts to overfit beyond this point.
How does overfitting happen?
There are several reasons for overfitting and i just want to talk about some of them.. there are many more
Data model to complex
Overfitting can be caused when the data model is to complex for the size of the dataset.
Usually you’re trying to minimise some kind of cost-function based on a training dataset, this is basically you trying to fit a line as close to each datapoint in the training set as possible. If you’re data model is complex enough there is almost always a way to exactly match the training set and therefore reduce the cost-function to 0.
The Problem with this is that your model fits the training data perfectly but when shown other data the performance of this model will be bad.
Parameter Tweak overfitting
Parameter Tweak overfitting is a type of overfitting introduced during parameter tuning of your model.
So if you have a look at the diagram with the training and test errors one would choose the model with the complexity relating to to minimal test error and would assume this models generalisation error would be equal to that test error.
But you used your test data to tune your model this means this data is no longer unseen by the model and should not be used to calculate the generalisation error.
One way to prevent this from happening would be to use one extra validation dataset which is used for parameter selection and tuning.
Choice of measure
Choosing the wrong measure of performance for your model could cause severe overfitting problems.
You should always choose a measure that is appropriate for the problem you are trying to analyse.
It is good to have several measures while validating the performance of your model but you should always have that one key measure for measuring improvement in performance.
One example for a bad measure would be using accuracy for a very imbalanced dataset. When 89% of data points are in the majority class of this dataset then an accuracy of 89% is not that great and should not be considered the final model.
Sampling
Chances are that your data has been run through some sampling processes before you split it into training and test sets. During this sampling process some data points may be duplicated and you could end up with the subset of same data points in both the train and test datasets.
Therefore your test dataset is no longer truly unseen and if the overlap is to big may become overestimated. So you should really check how much overlap there is after sampling. There will be some but you have to make sure that it does not affect your model too much.
How to prevent Overfitting
Although I already mentioned some ways to prevent overfitting in the examples of how overfitting happens, I want to talk here about general ways to prevent overfitting.
Collect more data
One of the more obvious ways to try to collect more data the more data you have the harder it is to actually overfit your model.
As an example take a training dataset with 3 data points.. it is fairly simple to draw a line to perfectly hit them all.. which kind of means that it is also simple for the model (or a function) to fit them perfectly… but now imagine a training set with 10,000 data points you would need a high polynominal function (or more complex model) to perfectly fit all those data points.
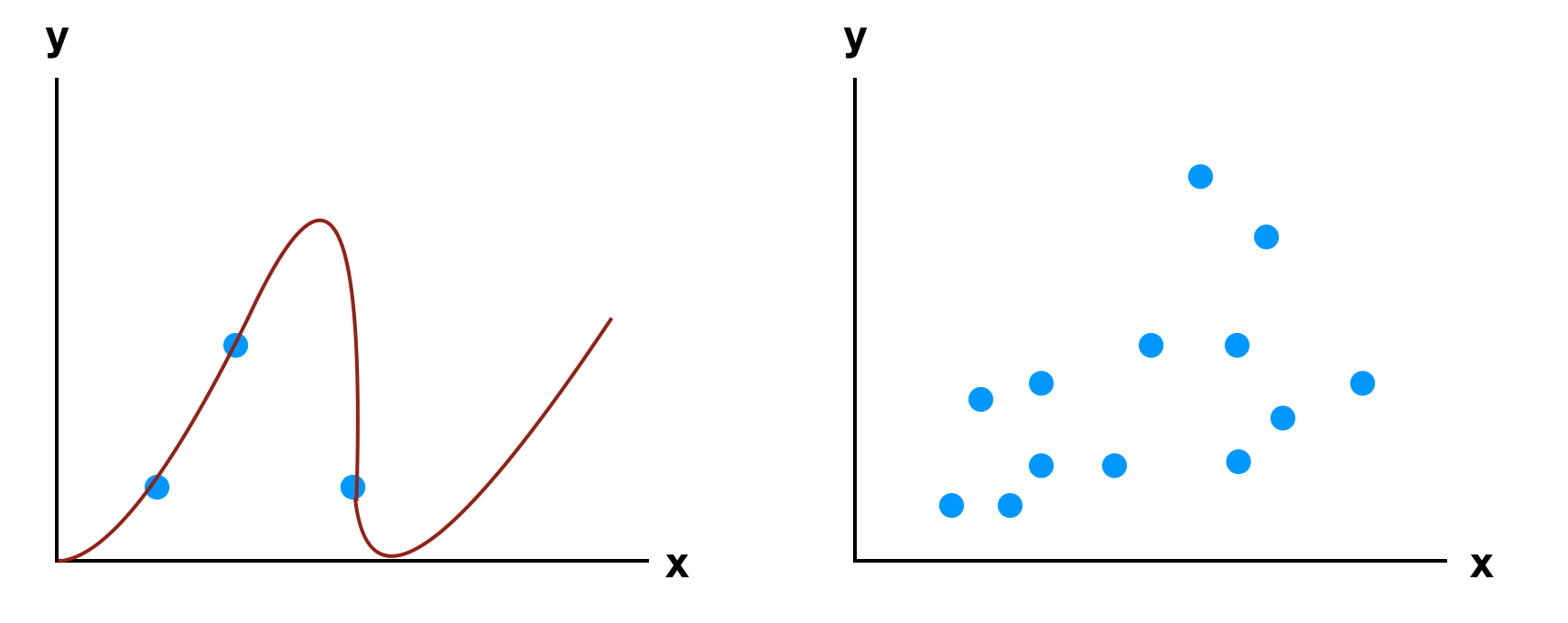
Keep the model simple
If you can’t get more data another way would be to try to keep your model simple. Try to reduce the number of independent parameters in your model. This is just the other way around of the collect more data example…
Regularization
There are Regularization-Algorithms that penalise complex models and help keeping them simple. Two examples for linear models would be "Ridge Regression" or “LASSO”, which penalise the model when the values of the coefficients get too high. Common machine learning libraries like scikit-learn have usually implementations for them that are easy to use in your model.
Cross-validation
Cross-Validation can also help to prevent overfitting when you can’t change model complexity or the size of the dataset. With cross validation you're basically enlarging your dataset synthetically because the percentage of your data “wasted” on the test set is smaller. So when using k-fold cross validation we divide the data into k subsets of equal size. We also build models k times, each time leaving out one of the subsets from training and use it as a test set.
Think
Try to get an idea why your model behaves like it is. Try to come up with explanations and try to figure things out. If something looks “just not right” investigate further. Use your common sense.
Be sceptical
Be sceptical about your model. If something looks to good to be true… it probably is.